This web page was produced as an assignment for an undergraduate course at Davidson College
My Favorite Yeast Protein
The purpose of this page is to explore databases and attempt to learn more about the structure and function of the proteins encoded by my favorite yeast genes MCA1 and YOR193W. Following this analysis, I will also design controlled experiments that, if performed, would provide further insight into the workings of these proteins.
MCA1 - Annotated Gene (YOR197W)
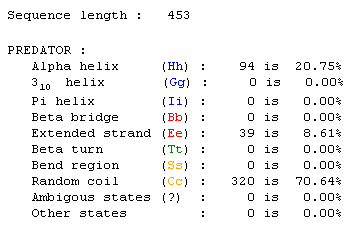
A study done by Szallies et al. showed that the protein encoded by MCA1 (MCA1p) is involved in apoptosis, cell mediated cell death. More specifically, MCA1 expression causes mitochondrial dysfunction that leads to cell death (Szallies, et al. 2002). The microarray data supports the notion that MCA1 is involved in apoptosis in some way. It suggests that the MCA1 protein likely functions as a positive control since it is expressed at times when apoptosis is probably taking place. We also know that MCA1p is an integral membrane protein judging from the Kyte-Doolittle analysis. A predator search revealed some information about the structure of MCA1p:
Figure 1: This Predator analysis shows that 20.75% of the protein is configured as an alpha helix while another 8.61% is an extended strand. Most of the protein however (70.64%) is involved in random coiling. Click on the information to find the page.
I went to the Pathcalling web page to try to learn more about MCA1p's protein-protein interactions. Here's a diagram of what I found:
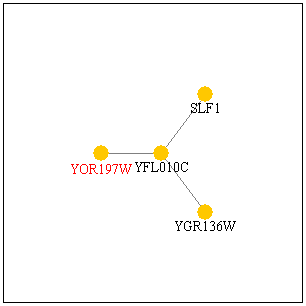
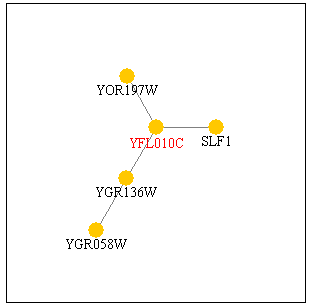
Figure 2: Right: This Pathcalling search for YOR197W, another name for MCA1, shows that the protein interacts with YFL101C which in turn interacts with SLF1 and YGR136W. Left: This diagram shows a larger interaction and how YOR197W fits into the picture. Click on the diagrams to view the site.
Note: I predicted earlier that MCA1 might be involved in mitochondrial dysfunction as method for causing cell death. The SGD page notes the nucleus as the location of MCA1 in the cell which would cause me to modify my earlier guess. Apoptosis, programmed cell death, will cause the nucleus to break down before the cell membrane which makes the nucleus a feasible location for this protein as well. I would also predict that since we know that it has a transmembrane domain that it is located in the nuclear membrane.
The SGD web site has a link called the Interactions Grid Database which showed that MCA1 was identified in association with seven other proteins. They have a variety of function and for three of them, the function is unknown. These related proteins with known function are an RNA polymerase II transcription mediators, a protein kinase, an mRNA binding, and an RNA polymerase II transcription factor.
When I clicked on apoptosis on the Interactions Grid Database section of the SGD it took me a site called Amigo that gave a good definition of apoptosis. It defined apoptosis as follows:
"The intracellular, controlled process characterized by condensation and subsequent fragmentation of the cell nucleus during which the plasma membrane remains intact. The process of apoptosis begins with external or internal signals which trigger, directly or indirectly, a cascade of caspases and results in death of the cell. Characteristics are membrane blebbing, DNA fragmentation and macrophage-mediate endocytosis."
This definition further suggests that MCA1, a caspase, is located in the nuclear membrane and involved in this apoptosis signaling cascade.
I searched the MIPS database and there were two hits found for YOR197W. Clicking on this link provides several pieces of information, most noteably the molecular weight (50.7 kD) and the isoelectic point (5.89). These two pieces of information are needed when analyzing a 2D gel. The isoelectic point is the pH at which a molecule will have a net charge of zero.
I searched the DIP (Database of Interacting Proteins) for both MCA1 and for YOR197W and no hits were found for either. If MCA1 was included in this database, it would provide a diagram of many of the genes that interact with MCA1. Protein interactions are extremely complicated and therefore these diagrams are complicated as well. The diagram looks like a bunch of dots connected by lines. The thickness of the lines indicates the probability that there is an interaction between the two proteins.
Next, I searched the different PDF files that we've covered in the proteomics chapter of this class. There were no occurrences of MCA1 or YOR197W on any of the three web sites searched.
I also searched the TRIPLES database and no records were found for MCA1 or YOR197W.
YOR193W - Non-annotated Gene
Not much is known about YOR193W and my research thus far has provided mere predictions. I can, however, use the databases above to try to learn more about the protein encoded by YOR193W. Our predictions about YOR193W so far have been that it might function in apoptosis because it is located very close to MCA1 on Chromosome XV. Obviously, there is a large chance that chromosomal location has absolutely nothing to do with protein function. After having studied proteomics for the past few weeks I feel even more weary about making this claim based solely on location data. Let's recall the predator search data for YOR193W:
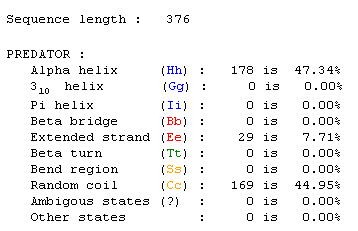
Figure 3: This predator search reveals that 47.34% of this protein is in an alpha helix configuration with most of the rest of the structure involved in random coiling with the exception of 7.71% that is an extented strand. It is difficult to make any solid prediction regarding function or location with this information. The numbers are somewhat similar to equivalent data for MCA1 but not close enough to draw any comparisons. Click on this data set to view site.
The Pathcalling web site has YOR193W listed but does not show that it is involved in any protein interactions as show by this diagram:

Figure 4: This diagram from the Pathcalling web site shows that there are no protein interactions listed for YOR193W. Since we know that most proteins interact, we might assume that this lack of protein interactions listed in merely a limitation of the database.
Next, I searched the Interactions Grid Database which is part of the SGD in another attempt to find proteins that interact with YOR193W. This database listed no proteins as being associated with YOR193W.

Figure 5: This screen shot from the Interactions Grid Database shows that little is known about YOR193W.
The MIPS database provided the molecular weight and isoelectric point for YOR193W. Its molecular weight is 44.1 kD and its isoelectric point is 10.49. (As noted above) These two pieces of information are needed when analyzing a 2D gel. The isoelectic point is the pH at which a molecule will have a net charge of zero. This site also stated that YOR193W shows a weak similarity to YPL112c. This is not a very significant piece of information but worth including here because it is the only information I've found regarding protein similarities with YOR193W.
I searched the DIP (Database of Interacting Proteins) for YOR193W and no hits were found. If YOR193W was included in this database, it would provide a diagram of many of the genes that interact with MCA1. Protein interactions are extremely complicated and therefore these diagrams are complicated as well. The diagram looks like a bunch of dots connected by lines. The thickness of the lines indicates the probability that there is an interaction between the two proteins.
Next, I searched the different PDF files that we've covered in the proteomics chapter of this class. There were no occurrences of YOR193W on any of the three web sites listed.
I also searched the TRIPLES database and no records were found.
What would I do?
To learn more about each of these proteins there are several experiments that could be done. In this section I will describe the experiments I would do to increase the knowledge about these proteins in the scientific community.
MCA1
Much is known about MCA1 as an individual protein. Its biological processes, molecular function as well as its sub cellular location are all fairly well documented. Although MCA1 is not listed in every database, the basic information is readily available. That said, my aim for experimentation with this protein would focus less on the qualities of MCA1 as an isolated gene or protein and more on its protein-protein interactions. I would attempt to uncover the complex pathways that it is a part of and try to zoom in on its specific role in this complex proteome.
First, I would do a knockout for MCA1. A knockout is when you literally remove a gene from a genome and analyze the development of an organism in its absence. Gene knockouts have advantages and disadvantages as a research tool. They can be extremely beneficial in determining whether or not a certain protein plays an essential role in one or more cellular processes. For example, if a knockout of MCA1 was made I would expect apoptosis to be effected in that colony of yeast. If the process was uneffected then I would conclude that there are alternate pathways for apoptosis that do not include the protein product of MCA1. The limitation of knockouts is that it's hard to get very specific with what role a protein plays. While I could determine that the cell is either affected or unaffected by the absence of MCA1, I would not be able to map any specific pathways or determine which proteins are interacting. Click here to learn more about gene knockouts.
To get more specific about the protein-protein interactions of MCA1 a yeast two-hybrid experiment would be helpful. The purpose of this method is to pick one protein to use as "bait" and determine what other proteins interact with it in the cell. I would choose MCA1 as my bait protein. There are several proteins that are already known to interact with MCA1, but this method could still be beneficial in having a more complete definition. Afterwards, I would analyze the proteins that interact and also the data from my knockout experiments to try and fully understand the biological processes of the cell in their most basic form. Click here to learn more about the yeast two-hybrid method.
These are only two examples of methods I might utilize given the time and money.
YOR193W
YOR193W is a bit of a different case because so little is known about it. Determining protein-protein interactions is important but first learning something about this protein itself takes priority. The first thing I would do would be an immunofluorescence. The purpose of this method is to determine where in the cell a protein is located and also an estimate of how much is being expressed. By putting a fluorescent marker on secondary antibodies for the target protein you can simply look at a picture to determine these two key pieces of information. I might predict that YOR193W will be located near the nucleus like MCA1 but without knowing much else about it, this is just a guess. Click here to learn more about immunofluorescence.
I would also perform a knockout for this gene as well as a yeast two-hybrid experiment to analyze protein-protein interactions (see explanations above). Again, predictions are difficult with so little known about this gene or its protein product.
Final Thoughts
The overwhelming message with proteomics is that there is almost an unlimited amount of information to be gathered. Once we determine the exact structure of a protein we want to know how much of it exists, where is it located and at what times in cellular development is it expressed. Beyond that, defining the exact role of each protein in all of the complicated process of the cell becomes pertinent. Even if we know every detail of the workings of one cell, can that be applied to other species or even other organisms within that species? Can we affect these processes to prevent disease and sickness? As we look deeper into the inter workings of the cells that make up all living organisms we truly realize how infinite the science that governs us can be.
References:
Szallies, A. et al. April 24, 2002. A metacaspase of Trypanosoma brucei causes loss of respiration competence and clonal death in the yeast Sacchoromyces cerevisiae. FEBS Lett. 517, 1-3: 144-150.
This page was designed by Graham Watson, a senior Biology major at Davidson College.
Click here to go back to my Home Page
![]()
![]()
© Copyright 2003 Department of Biology, Davidson College, Davidson, NC 28035
Send question to grwatson@davidson.edu