Proteomics of YMR279C & CAT8
Quick Review |
CAT8 and YMR279C are located side-by-side around 820 kilobases down the crick strand of the thirteenth chromosome of Saccharomyces cervisiae, baker's yeast. CAT8 has been annotated with ontological information; YMR279C has not. To investigate YMR279C's potential function, we initially analyzed the hypothetical gene in terms of its nucleic- and amino-acid sequence. This revealed a number of conserved domains common to transport proteins (although BLAST searches did not turn up any significant homologs), and a Kyte-Doolittle hydropathy plot predicted 7+ trans-membrane domains, indicating YMR279C potentially encoded some kind of transporter or channel protein. CAT8, on the other hand, had already been well-characterized as an important early regulator of the diauxic shift, and its enormous and complicated sequence seemed consistent with its transcriptional role. Analysis of expression patterns revealed YMR279C tended to cluster with other trans-membrane proteins, particularly sugar transporters, supporting its potential transporter identity. CAT8 was hard to characterize in the same manner; it never experienced more than modest changes in expression, probably because of its regulatory role.
The next step in understanding my two favorite yeast genes is to examine proteomic data. hard to predict how much will be available: CAT8's relatively low levels of expression and large and complicated shape may have made it difficult to obtain; on the other hand, it interacts (transcriptionally) with a least 34 other genes, and this may have been a compelling reason to do so anyway. YMR279C seems like it would be a bit easier to experiment with, given it's probable trans-membrane location and similarity to already-understood proteins, but by the same token perhaps it isn't interesting enough to garner individual attention. Hopefully it will have been manipulated in experiments based on massive screens. We shall see...
Methodology |
|
There are almost too many database out there. One of the biggest challenges is going to be spanning all the possible ways of interacting with the data in the most efficient manner i.e. finding the set of websites that are collectively the least redundant. It is great to find one website providing data that confirms another website, but its almost pointless if they both use the same database as their source, if they are not independent.
That said, I will investigate each of my two favorite genes in two general ways: by compiling its interaction data and by developing its 3D structure. To aid in the research process, I have attempted to survey a modest amount of the online resources and categorize them, or their subsites, on the basis of what type of information they may provide. Several sites act as portals to all the other databases, helping to provide a centralized point of interaction and knitting together their individual data into a collective patchwork.
Portal-sites:
- NCBI - NCBI Gene
- Ensembl - Explore the S. cerevisiae genome
- SGD - Saccharomyces Genome Database
- ExPASy - Expert Protein Analysis System (and my favorite)
- MIPS - Comprehensive center for yeast genomics
- Gene Quiz - not as polished, but I like the authoritative function annotations
Interaction:
- KEGG - use accession from ExPASy
- DIP - Database of Interacting Proteins
- IntAct - Protein interaction derived from literature or submitted
- MIPS - protein-protein interaction
- GRID - yeast grid
- TRIPLES - phenotypic, localization, and expression data
- STRING - Search Tool for the Retrieval of Interacting Genes/Proteins (my favorite!)
- YeastGFP - Protein localization studies w/ GFP in budding yeast
- BIND - BIND is no more! "curation activities has been terminated"
Structure:
- Swiss-Prot/trEMBL - curated protein sequence database
- PROSITE is a database of protein families and domains
- ModBase - 3D protein models calculated by comparative modeling
- SMART - sequence analysis
- Swiss-2DPAGE - I.D.ed proteins & SDS-PAGE reference maps
- PDB - protein data bank
A lot of the portal sites link directly to the more specialized databases. I was very impressed with the ExPASy website and all the related databases (anything w/ Swiss, ModBase, etc.). They consistently gave me good results. (Check out Gene Quiz - it's not as visually polished, but I think it sometimes provides deeper info for a given gene than the other portals.) I thought quite a few of the interaction sites seemed to have the same data (DIP, IntAct, MIPS, GRID; at least, each produced only one interaction for either of my genes, and it was the same amongst all four sites. Maybe it's just an indication that there isn't much info available for my genes).
So, with this list of sites, for each of my two genes I proceed in this order:
1. Conduct fulltext search at the PDB for a 3D crystal solution.
2. Find the gene in Uniprot at ExPASy. Use the tools provided to calculate molecular weight and isoelectric point.
3. Go to SWISS-2DPAGE link in the UniProt and find a 2D gel.
4. Use YeastGFP to get cell localization info.
5. Check TRIPLES for interaction data.
6. Check STRING for an interaction map.
7. Check SMART (normal mode), Interpro, PROSITE for conserved domains.
8. Get the predicted structure from ModBase. Compare.
Proteomics of CAT8 (YMR280C) |
|
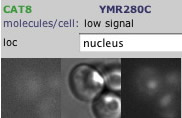 Fig. 2: CAT8 was tagged with Green Fluorescent Protein to indicate its typical location in yeast, which seems to be the cytoplasm and the nucleus. Permission pending: yeastgfp. (note: open this link with microsoft ie for full functionality) |
 Fig. 3: mTn was inserted into CAT8 grown under constant and sporulative conditions. Both produced strong blue. (get citation from site) Permission pending: TRIPLES |
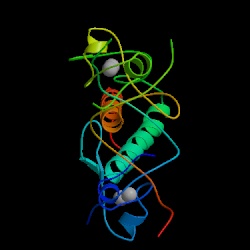
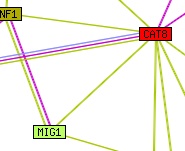 Fig. 4: Network of predicted interactions with CAT8. "Edges (putative links between orthologous groups) consist of up to three lines: a red line indicates the presence of fusion evidence for the link; green - neighbourhood evidence; blue - phylogenetic coocurrence evidence. A bold line indicates particularly strong evidence in each case."- Permission pending: STRING. |
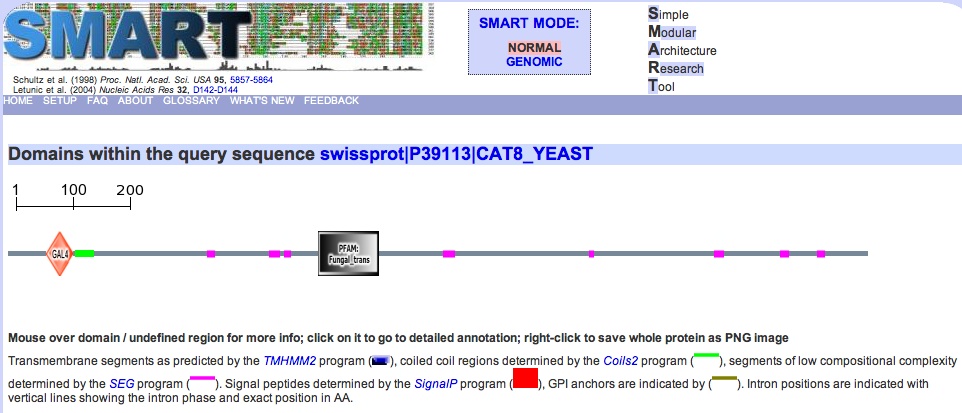 Fig. 5: Conserved domains in CAT8. Green indicates coiled-coil domain, and pink indicates regions of low complexity. E-value for GAL4 domain = 2.70e-13, for PFAM = 9.70e-29. Permission pending: SMART. |
1. Fulltext search for "YMR280C" at PDB:
"Your query found NO structures in the current PDB release or in the PDB holdings database"
2. UniProt entry for search term "YMR280C":
Entry name: CAT8_YEAST
Primary Accession Number: P39113
Molecular Weight: 60485.47
Theoretical pI: 9.13
3. SWISS-2DPAGE link:
"This protein does not exist in the current release of SWISS-2DPAGE."
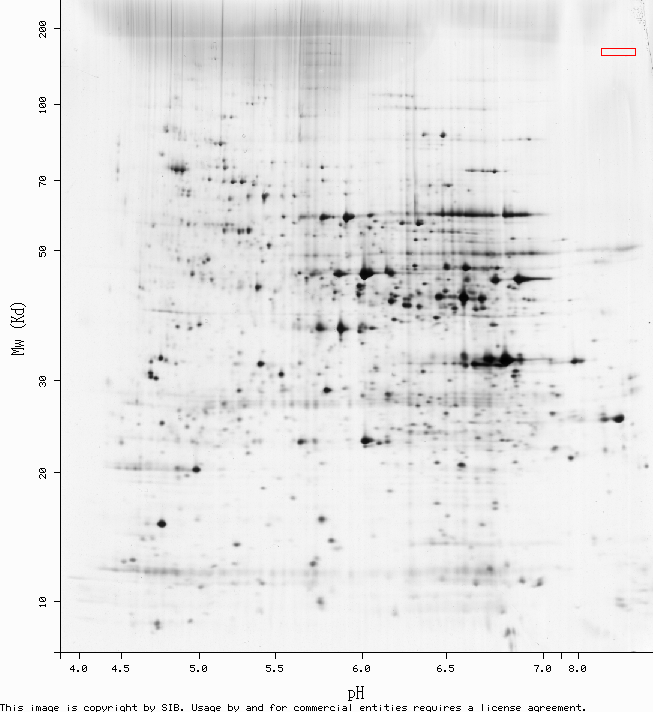
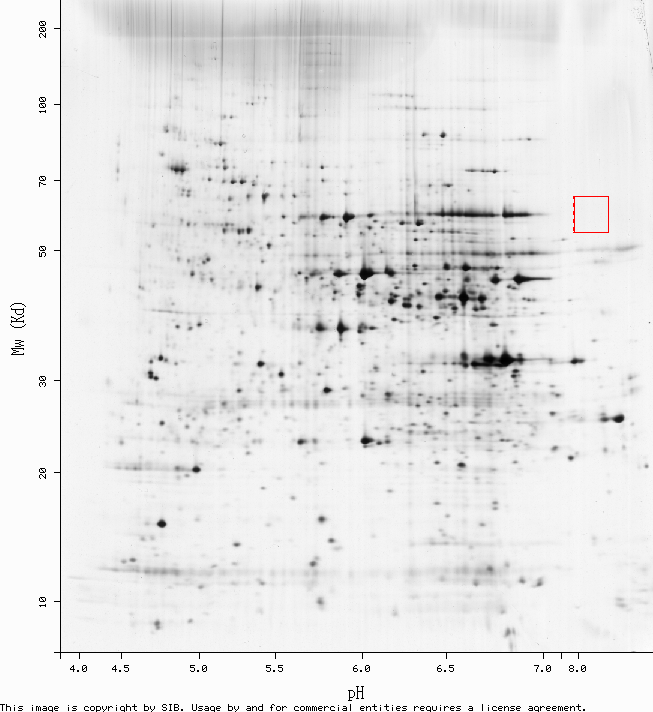
>Opened Yeast 2D PAGE map for unidentified proteins (fig. 1).
2D PAGE is a procedure for physically separating a solution of proteins based on their molecular weight and isoelectric point. It begins just like any other gel electrophoresis, with the proteins migrating down an electrical gradient at speeds dependant on their molecular weight. Then the scattered proteins are exposed to another electrical gradient perpendicular to the first. This new voltage drives them across a gel that has been prepared with a pH gradient, which alters the net charge of the proteins as the progress across it.
It doesn't work very well for really small proteins or really basic ones, or proteins that are particularly hard to solubilize. The red box in fig. 1 is where we would expect to find CAT8, given its molecular weight and pI... but it doesn't seem to be present. One explanation is that with all of its tran-membrane domains and funky DNA-binding sites, CAT8 is one of the proteins that's hard to solubilize. And/or compared to the genes it regulates, CAT8 is probably rarely expressed very high at all, since not much of it is needed to excercise transcriptional control. Perhaps there just wasn't much in the sample.
4. Yeast GFP Fusion Localization Database search for "YMR280C" (fig. 2):
The localization data isn't shocking - CAT8 was detected in minor amounts in both the cytoplasm and in the nucleus, which is what we might expect for a transcriptional regulator. It needs to be in the nucleus to act on the DNA, and it probably is present in the cytoplasm because a) that's where it is translated, and b) that is where it becomes functionally active.
5. Results of mTn insertion into CAT8 from TRIPLES (fig. 3):
One method developed for conducting high-throughput screens of gene function involves inserting some kind of reporter sequence into a gene such that the gene is made non-functional but the reporter sequence can still be transcribed. Growing cells mutated in this manner - note that the same reporter can really only be used once per genome - in a variety of environments leads to phenotypic differences that can be easily associated with a particular gene, or lack thereof.
In this case, the knockout gene happened to be CAT8. The intensity of the reporter is directly proportional (in theory) to the amount the knockout gene would have been transcribed in that environment. It seems that CAT8 is transcribed quite a bit in both resting (vegetative) and the more energetic reproductive (sporulation) growth.
6. Predicted YMR280C interaction map from STRING (fig. 4):
Figure 4 represents CAT8's interactions with several other genes, most of which are also regulators.
7. Domains in "YMR280C" as indicated by SMART (fig. 5):
There are two interesting domains visible in the screenshot, GAL4 and Fungal specific transcription factor domain. Both seem to involve binding with Zinc, and may be very similar to one another; the Fungal specific transcription factor site actually indicates that the factor is found in GAL4, which seems paradoxical when looking at fig. 3 - GAL4 is not large enough. Additionally, the diagram doesn't show a Fungal Zn(2)-Cys(6) binuclear cluster domain, (1.70e-13, Prosite entry) which is completely occluded by GAL4. Although the structure of CAT8 has not yet been solved, that of GAL4 and Fungal Zn(2) has. We will check these structures out next.
8. Predicted 3D structure of CAT8 from ModBase:
1pyi (from PDB)
1pyi is a homodimer, and the structure ModBase generated is the monomer form. 1pyi is also associated with GAL4
Proteomics of YMR279C |
|
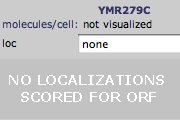 Fig. 7: Yeast GFP Fusion Localization database query for YMR279C. Permission pending: yeastgfp. (note: open this link with microsoft ie for full functionality) |
 Fig. 8: mTn was inserted into YMR279C grown under constant and sporulative conditions. Both produced faint blue. Additionally, Permission pending: TRIPLES |
 Fig. 9: Network of predicted interactions with YMR279C.. "Edges (putative links between orthologous groups) consist of up to three lines: a red line indicates the presence of fusion evidence for the link; green - neighbourhood evidence; blue - phylogenetic coocurrence evidence. A bold line indicates particularly strong evidence in each case."- Permission pending: STRING. |
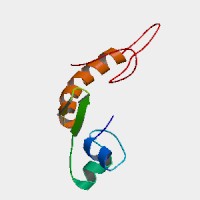
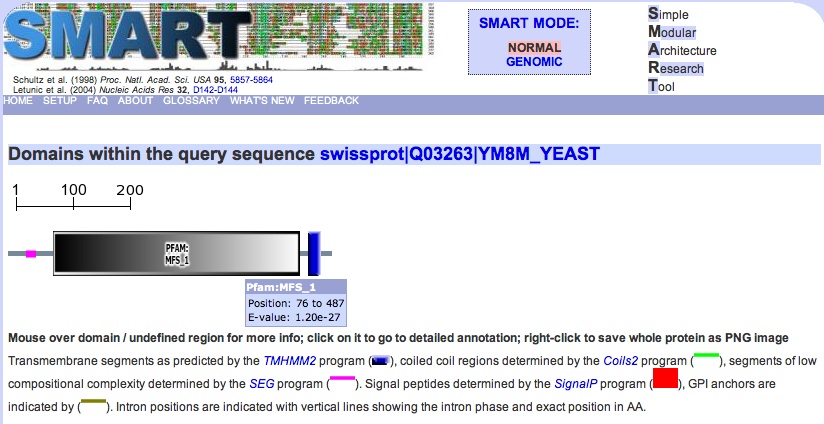 Fig. 10: Conserved domains in YMR279C. Green indicates coiled-coil domain, and pink indicates regions of low complexity. The biggest domain by far is MFS_1 (1.20e-27). Permission pending: SMART. |
1. Fulltext search for "YMR280C" at PDB:
"Your query found NO structures in the current PDB release or in the PDB holdings database"
2. UniProt entry for search term "YMR279C":
Entry name: YM8M_YEAST
Primary Accession Number: Q03263
3. SWISS-2DPAGE link:
"This protein does not exist in the current release of SWISS-2DPAGE."
>Opened Yeast 2D PAGE map for unidentified proteins (fig. 6):
Nothing in the expected area in this 2D PAGE, either. Maybe this part of chromosome 13 was deleted or something...
4. Yeast GFP Fusion Localization Database search for "YMR279C" (fig. 7):
YMR279C was not in the database.
5. Results of mTn insertion into YMR279C from TRIPLES (fig. 8):
YMR279C was knocked out when a LacZ reporter sequence was inserted, and this time around the sample was run through a battery of different conditions (in retrospect, perhaps they just didn't bother with CAT8 since it was already annotated..?). Interestingly, they identified two norfs, or short stretches of dna (>100) assumed to be non-functional, that apparently caused a phenotypic change when they were interrupted. One of them is only 15 aa long!
The lacZ expression data seems to indicate YMR279C isn't heavily transcribed. If it is an organic transporter of some kind, I can't really imagine any time a cell would need a lot of them really fast! So I suppose these results are consistent. Despite the large table of Disruption Phenotype Data, none of it seems particularly meaningful.
6. Predicted YMR279C interaction map from STRING (fig. 9):
This is a beautiful and comprehensive (if not a little whimsical) map of interactions between YMR279C and other genes. It was initially a bit surprising, because all the other interaction databases only ever provide one other gene for YMR279C to play with: ATP10. None of the genes in this graph have a particularly high score, and besides ATP10, which was also experimentally found, all interactions are based on coexpression data alone. This information is graphically present in the color of the edges between genes. So, YMR279C doesn't seem to interact with a wide variety of proteins, or even a medium variety of proteins - it seems fairly specific (like a transporter might need to be!).
7. Domains in "YMR279C" as indicated by SMART (fig. 10):
You can see from the figure that the Major Facilitator Superfamily (MFS) domain occupies the majority of YMR279C's sequence. It's so big that we might expect it to be occluding other domains, and it is, technically, but they are mostly just trans-membrane domains with a couple of "regions of low complexity."
Identifying this domain was really important, because the documentation for it at PROSITE indicates that the MFS domain essentially defines one of the two most ubiquitously occurring classes of natural transporters, found across all classifications of organisms, the other class being defined by the ATP binding cassette (ABC) primary transporter superfamily. Transporters in the ABS superfamily are all able to accomplish active transport "on their own," so to speak, (hence the primary designation), unlike those belonging to the MFS superfamily, which can only transport small solutes in response to chemiosmotic ion gradients.
I think it's fairly clear that YMR279C is a transporter of some small molecule, perhaps a sugar, or perhaps a nitrate/nitrite or phosphate transporter, which are only present in fungi and plants, and some bacteria.
8. Predicted 3D structure of CAT8 from ModBase:
1PV6 (from PDB)
1PV6A is the template code that ModBase used to generate its model, so that's what I am designating it as above (even though its probably not technically correct.). Apparently ModBase can't predict structure if no domains of known structure are present in the template sequence. I don't quite understand the statistics presented on the page for the IPV6, but the template sequence used to generate "IPV6A" had 14% sequence identity with our query sequence YMR179C, and a BLAST e-value of 5e-20. So what was the template sequence? 1PV6 is the pdb file for the E. coli Lactose permease protein! This is particularly interesting because that protein is a member of the LacY-like proton/sugar symporters, and hence YMR279C might be as well. In fact, I wonder if YMR279C had any effect on the knockout trials that used LacZ? I suppose not, for if LacZ had broken YMR279C, and YMR279C was the only suitable LacZ transporter, then we wouldn't observe the telltale blue surrounding the cell, would we? Or would it still be present, but just at reduce amounts? Hmm.
Summary & Conclusions |
So, we learned what CAT8 does (transcriptional regulator that is a key player in the early stages of the diauxic shift), and used it as a sort of positive control throughout the course of these three webpages. Working through the process of discovery for something that was already rather well discovered was a good way to test my methodology; if I used a database incorrectly with CAT8, I was far more likely to see it than if I had just been working in the dark, on the unannotated gene alone.
And I think I really got somewhere with YMR279C. I know now that the conserved domain data was available the whole time, but I don't think I ever would have found it for the first sequence-only assignment, (perhaps because I was looking in the wrong database!) In any case, because of the huge Major Facilitator Superfamily domain that seems to form the core of YMR279C, I feel fairly confident in the assuming that it is a secondary transporter of some kind. Still, it hasn't been annotated yet, and I am certain that it could be better characterized purely with free online tools data, (perhaps by comparing YMR279C to groups of very specific transporters using sequence tools and expression data), but for now, at least, YMR279C is annotated in my mind.
References |
- ExPASy Proteomics Server
- NCBI Entrez Gene
- Mips - Comprehensive Yeast Genome Database
- Ensembl - Saccharomyces cerevisiae
- Saccharomyces Genome Database
- GeneQuiz - Home page
- Welcome to PIR [Protein Information Resource - uses UniProt]
- YEAST GRID (S. cerevisiae Interaction Datasets)
- DIP: the Database of Interacting Proteins
- KEGG: Metabolism - Reference pathway
- TRIPLES - transposon-insertion phenotype, localization, and expression in yeast
- NCBI Entrez Gene
Home • Trim5α • MFYG:Sequence • MFYG:Expression • MFYG:Proteomics • Campbell's Genomics
© Copyright 2005 Department of Biology, Davidson College, Davidson, NC 28035
Send comments, questions, and suggestions to: macowell "at" davidson.edu